
Chatbots with Memory using LangChain
Part 3 of the series "Everything You Need to Know About LangChain (Before Starting an AI Project)"

Welcome to the third post in our series on LangChain!
In the previous posts, we explored how to integrate multiple LLMs and implement RAG (Retrieval-Augmented Generation) systems.
Today, we’re taking a key step toward making chatbots more useful and natural: chatbots with conversational memory.
Why Chatbots with Memory?
Imagine talking to someone who forgets everything you said 30 seconds ago. Frustrating, right? 😅 That’s exactly the experience users have with chatbots that lack memory. Each question is treated as if it were the first interaction, leading to disconnected conversations and a limited user experience.
Memory in chatbots enables:
Conversational continuity: The bot remembers the context of the conversation
Personalization: Adapts to the user's style and preferences
Efficiency: Avoids repeating information already provided
Natural experience: Simulates how humans actually talk
Use Cases
Personal assistants that store user preferences and information
Customer support that tracks interaction history
Virtual tutors that remember a student’s progress
Game chatbots that maintain storyline and player decisions
How Does Memory Work in Practice?
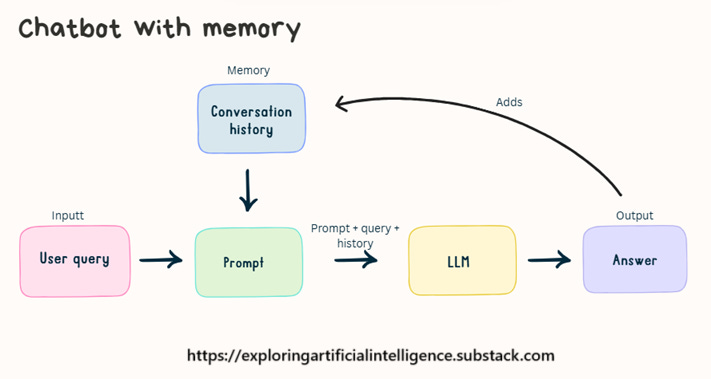
A chatbot’s memory doesn’t reside within the language model (LLM) itself — LLMs are stateless and don’t retain information between interactions.
What creates the illusion of continuity is that the conversation history is stored externally and, with each new user input, this history is retrieved and appended to the prompt sent to the model.
In other words, the LLM generates a response based on everything it sees in that moment, as if it's seeing the entire conversation for the first time.
Follow our page on LinkedIn for more content like this! 😉
It works like this: each time the user sends a new message, the history of previous messages (both inputs and outputs) is concatenated to the prompt. In other words, the model receives not just the new question, but also a record of the conversation up to that point as context.
This means that:
The model doesn’t remember on its own. It seems to remember because the history is being included with each new input.
Memory is reactive: the model responds based on the previous messages we choose to include.
That’s why context window size matters. If the history gets too long and exceeds the model’s token limit, it must be summarized, truncated, or stored differently.
How Does LangChain Help Build Chatbots with Memory?
LangChain provides built-in structures and tools to manage conversation history and make it easier to implement this kind of contextual memory.
When building a chatbot with LangChain, you configure a memory component that stores both the user inputs and the assistant’s responses. On the next interaction, this memory is passed along with the new input to the model — allowing it to generate responses that are more coherent and aligned with the conversation’s flow.
An Example:
from langchain.prompts import PromptTemplate
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
from langchain_google_genai import ChatGoogleGenerativeAI
import os
# Set your Gemini API KEY
os.environ["GOOGLE_API_KEY"] = API_KEY
template = """
You are a virtual assistant who responds politely and concisely.
Conversation history:
{history}
User: {input}
Assistant:"""
prompt = PromptTemplate(
input_variables=["history", "input"],
template=template,
)
# Create conversational memory
memory = ConversationBufferMemory(memory_key="history")
llm = ChatGoogleGenerativeAI(model="models/gemini-1.5-flash", temperature=0.3)
# Create the conversation chain
conversation = ConversationChain(
llm=llm,
memory=memory,
prompt=prompt,
)
# First question
resposta1 = conversation.invoke({
"input": "Hi, how are you? My name is Maria. And you?",
})
print("Response 1:", resposta1["response"])
Response to the first question:
Response 1: Hi Maria, I’m good!
Now let’s ask if the chatbot remembers the user’s name:
# Second question to test memory
resposta2 = conversation.invoke({
"input": "Hi again. What’s my name?",
})
print("Response 2:", resposta2["response"])
Response to the second question:
Response 2: Hello! Your name is Maria.
Voilá! This is a simple example that demonstrates how the chatbot managed to “remember” the user’s name.
🚀 To access the code with more examples of chatbots with memory using LangChain, including an example with LangGraph, visit our Colab Notebooks area, where you’ll find ready-to-run notebooks! Look for
LangChain-chatbot-memory.ipynb.
The framework also offers different types of memory, each suited for specific scenarios, such as:
1. ConversationBufferMemory
The most basic type of memory - it stores the entire conversation in a simple buffer. It's ideal for short conversations where you want to keep all the context available. However, it can become problematic in long conversations due to the LLMs’ token limit.
2. ConversationBufferWindowMemory
A smart evolution of buffer memory, this keeps only the last N interactions. It’s like having a “sliding window” of the conversation, preserving the most relevant recent context while discarding older interactions.
3. ConversationSummaryMemory
This is where things get interesting. Instead of storing all the messages, this memory creates progressive summaries of the conversation. As the chat evolves, summaries are updated - keeping key information without overwhelming the context window.
4. ConversationSummaryBufferMemory
The perfect combination of both worlds: it retains complete recent messages and summarizes older ones. It’s like having a good short-term memory plus long-term memory summaries.
5. ConversationEntityMemory
This type of memory extracts and retains information about specific entities (people, places, concepts) mentioned during the conversation. It’s especially useful for chatbots that need to remember specific details about users or topics.
Memory Persistence
An important aspect is where and how memory is stored. LangChain offers different options:
Session memory: Stored only during the current session — ideal for temporary conversations.
Persistent memory: Saved in databases (Redis, PostgreSQL, MongoDB), allowing users to resume conversations in future sessions.
Distributed memory: For applications with multiple instances, using shared stores.
Challenges and Solutions When Working with Memory
Token Management
LLMs have token limits (context windows), and long conversations can exceed these. Strategies include:
Automatically summarizing older messages
Smart truncation while keeping relevant context
Memory compression based on importance
Privacy and Security
Storing conversations raises important concerns:
Encryption of sensitive data
Retention and deletion policies
LGPD (Brazilian GDPR) compliance
Anonymization of personal data
Performance
Memory can introduce latency. Some optimizations include:
Caching frequently accessed memory
Asynchronous memory updates
Efficient indexing of conversational data
What Comes Next? LangGraph
For those looking to go further, it’s worth exploring LangGraph, a tool that lets you create more structured conversational flows using state graphs.
LangGraph provides a modern, flexible approach to managing state/memory compared to traditional LangChain chains.
How Memory Works with LangGraph
LangGraph uses the concept of a state that persists across graph executions. You can define a custom state that includes conversation history, and that state is maintained automatically.
Traditional LangChain: Uses predefined memory classes (like
ConversationBufferMemory, etc.)LangGraph: You define your own custom state, giving full control over how memory is managed
Advantages of LangGraph for Memory:
Greater flexibility: You control exactly what is stored and how
Complex state: You can maintain multiple types of information beyond just history
Native persistence: Easily integrates with various storage backends
Flow control: You can create conditional logic based on memory/state
Conclusion
Implementing memory in chatbots using LangChain completely transforms the user experience, creating more natural, contextual, and efficient conversations. With the right tools and a well-structured architecture, it’s possible to build chatbots that not only answer questions, but truly understand and adapt to users.
LangGraph represents the next step in this evolution, allowing the creation of truly intelligent agents with complex and adaptive flows. As these technologies continue to advance, we’re getting closer and closer to AI assistants capable of holding deeply human-like conversations.
This is the third post in the series on LangChain. Check out the previous posts on LLM integration and RAG implementation, and stay tuned to get a full picture of what this powerful framework can offer.