
DeepSeek-OCR and the Future of Context Compression
A picture is worth a thousand words: what DeepSeek-OCR reveals about optical context compression


Imagine reducing the size of a text by ten times without losing almost any information. Now imagine doing this not with traditional compression algorithms, but with images.
That’s exactly the idea behind DeepSeek-OCR, a new model developed by the DeepSeek-AI team that brings together computer vision and natural language in an innovative way.
DeepSeek-OCR isn’t just another OCR system (optical character recognition). It’s a proof of concept that explores a fundamental question:
How many visual tokens are needed to decode 1,000 words of text?
The surprising answer: with only 100 visual tokens, the model can decode documents containing more than 1,000 text tokens, achieving 97% accuracy at a 10× compression rate.
Follow our page on LinkedIn for more content like this! 😉
The Problem DeepSeek-OCR Solves
Large Language Models (LLMs) face a major computational challenge when processing long texts, due to the quadratic growth in complexity as sequence length increases.
The solution proposed by DeepSeek is both ingenious and elegant: use the visual modality as an efficient medium for textual information compression.
The logic is simple but powerful, a single image containing text can represent rich information using far fewer tokens than the equivalent digital text. This paves the way for “optical context compression,” a new approach to handling long contexts in LLMs.
DeepSeek-OCR puts forward a bold idea: transform text into images and use vision as a means of compression.
Architecture: DeepEncoder + DeepSeek-3B-MoE
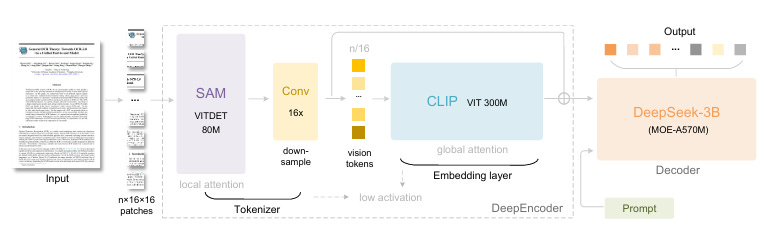
This new approach, called optical context compression, uses a hybrid architecture: the DeepEncoder, responsible for converting documents into highly compact “visual tokens,” and DeepSeek-3B-MoE, the decoder that reconstructs the original text.
In practice, this means a single image can represent thousands of words efficiently.
Results
According to the authors, DeepSeek-OCR achieved 97% accuracy when decoding text at a 10× compression rate.
Even with 20× compression, it maintained around 60% accuracy, which is remarkable for such a demanding task.
On benchmarks like OmniDocBench, the model outperformed well-known competitors such as GOT-OCR 2.0 and MinerU 2.0, while using fewer than 800 visual tokens per page, compared to the thousands required by others.
This places DeepSeek-OCR among the most efficient models in the world for reading and interpreting complex documents.
Advanced Capabilities: “Deep Parsing”
Beyond traditional OCR, DeepSeek-OCR demonstrates impressive deep parsing abilities:
Charts: Converts charts into structured HTML format
Chemical formulas: Recognizes and converts them into SMILES notation
Plane geometry: Can structure simple geometric figures
Natural images: Generates dense and detailed descriptions
Multilingual Support
Recognizes text in around 100 languages, supporting both layout-aware and pure OCR modes.
General Visual Understanding
The model also retains basic VLM (Vision-Language Model) capabilities:
Image description
Object detection
Grounding (locating specific elements within an image)
Forgetting Mechanism
One of the paper’s most intriguing ideas is using optical compression to simulate the human memory forgetting process:
Recent conversations: Kept in high resolution (Gundam / Large mode)
1 hour ago: Reduced to Base mode (~10× compression)
1 day ago: Small mode (~12× compression)
1 week or more: Tiny mode (~15–20× compression)
Just like human memory fades over time, text rendered at lower resolutions naturally “forgets” details while retaining the core meaning of the information.
How to Use
🚀 A practical example for running optical recognition with the model is available on Google Colab: DeepSeek-OCR.ipynb.
Conclusion
DeepSeek-OCR is not just another OCR model, it’s a proof of concept demonstrating the feasibility of optical context compression.
With the ability to achieve 10× near-lossless compression and 20× with controlled degradation, the model offers a promising path to solving long-context challenges in LLMs.
The innovative DeepEncoder architecture, combined with an efficient MoE decoder, sets new performance standards while using dramatically fewer visual tokens than its competitors.
More importantly, the optical compression paradigm opens new possibilities for rethinking how visual and linguistic modalities can be combined to improve computational efficiency in large-scale text processing and agent systems.
Links
License: Open-source (MIT), with public access to both code and model weights.
This is a fascinatig breakthrough in how we think about context windows. The idea of using visual compression to mimick human memory degradation is particularly clever - recent information stays sharp while older context naturally loses detail. I'm curious how this approach would scale with mathematical notations or code snippets compared to standard text.