
DeepSeek: What is it and why is it attracting so much attention?
A new Chinese model promises top-tier performance at a reduced cost compared to proprietary models.


The field of large language models (LLMs) has been evolving rapidly, increasingly approaching an advanced level of intelligence.
Last week, a new AI model gained significant attention. DeepSeek-R1, developed by the Chinese startup DeepSeek, is an innovative model that enhances its reasoning capabilities through reinforcement learning (RL), without relying solely on supervised fine-tuning.
The model maintains performance comparable to the most advanced models in complex reasoning and coding tasks, such as OpenAI-o1, with much lower training costs.
Furthermore, the company's models are open-source, democratizing access to AI and opening doors for research, small businesses, and innovation.
So, what is DeepSeek?
The model making headlines is DeepSeek-R1, designed to improve the reasoning capacity of LLMs using a multi-stage training approach.
Its predecessor, DeepSeek-R1-Zero, was trained directly via large-scale reinforcement learning (RL), without supervised fine-tuning (SFT) as a preliminary step, already demonstrating remarkable reasoning capabilities. While DeepSeek-R1-Zero developed powerful and intriguing reasoning behaviors, it faced challenges like low readability and language mixing.
To address these issues and further enhance reasoning performance, DeepSeek-R1 introduced a refined approach, including a "cold start" with initial data and an intermediate supervised training phase.
Key Features of DeepSeek-R1
Now, let's look at the main features of DeepSeek.
Pure Reinforcement Learning
DeepSeek-R1-Zero showed that a model can develop reasoning skills without the need for supervised fine-tuning. This means the model learns to think on its own, following reward-based incentives.
Multi-Stage Training Pipeline
DeepSeek-R1 starts its training with a small set of high-quality data to avoid initial fluctuations in RL. It then undergoes multiple stages of RL and supervised fine-tuning.
Distillation for Smaller Models
DeepSeek-R1 has also been used to distill its knowledge into smaller models, such as those based on Qwen and Llama. This enables more efficient models without sacrificing reasoning capabilities.
Results
In reasoning benchmarks, DeepSeek-R1 achieved results comparable to OpenAI-o1-1217, demonstrating excellence in tasks such as mathematics, coding, and general knowledge.
It also scored 97.3% on MATH-500 and excelled in programming competitions, outperforming 96.3% of participants on Codeforces.
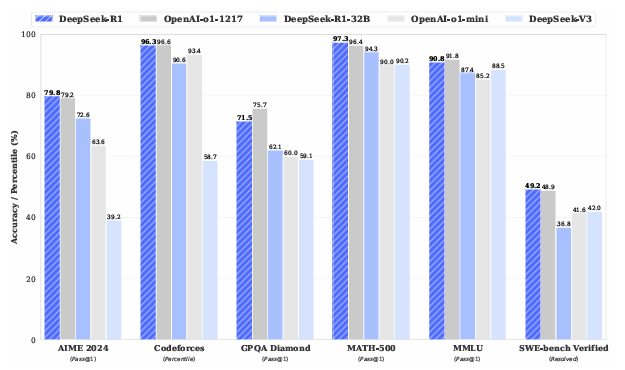
In the figure above, we can see the performance of DeepSeek-R1 compared to other models across various benchmarks, where it achieved results similar to the OpenAI-o1 model, with better results in 3 out of 6 evaluations.
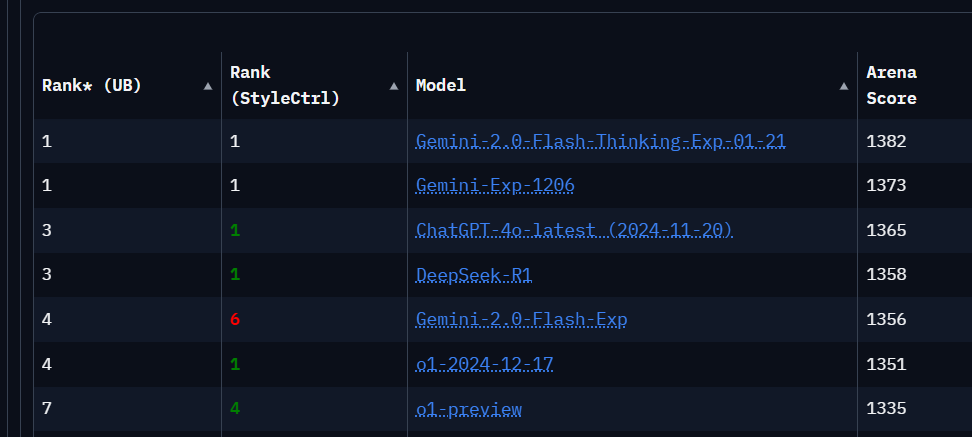
On ChatbotArena, a web platform that allows us to compare various LLMs in interactive battles, DeepSeek-R1 ranks 3rd, tied with ChatGPT-4o-latest (only behind the powerful Gemini-Exp from Google).
How to Run DeepSeek Locally?
To run DeepSeek on your computer without needing GPUs, we can use a distilled model with fewer parameters.
