

From LoRA to QLoRA: The Next Step in Efficient LLM Personalization

In the previous post, we explored how LoRA works, a technique that revolutionized fine-tuning by allowing only a fraction of a large language model’s parameters to be trained.
An elegant, efficient, and accessible solution for adapting models like LLaMA to new tasks with reduced memory usage.
Now, we move into the next phase of this journey: QLoRA.
QLoRA (Quantized LoRA) takes things a step further by combining low-cost adaptation with extreme quantization, reducing the base model’s weights to just 4 bits—without significant performance loss.
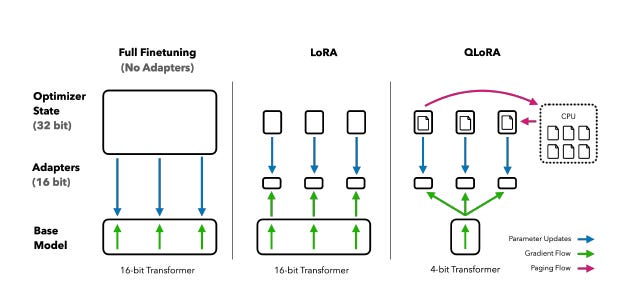
What’s the practical impact of this?
QLoRA enables:
Training models with up to 65 billion parameters on a single 48GB GPU
Achieving results close to (or even better than) ChatGPT, using only open data
Drastically reducing the computational and energy cost of fine-tuning
How does it work?
QLoRA combines three key innovations:
NF4 (NormalFloat 4-bit): A data type tailored for normally distributed weights, more effective than traditional FP4 and INT4
Double Quantization: Even the quantization factors are quantized, saving even more memory
Paged Optimizers: Prevent memory spikes during training on resource-limited machines
Follow our page on LinkedIn for more content like this! 😉
Applying QLoRA in Practice
When we talk about QLoRA, we’re combining two powerful techniques: 4-bit quantization using BitsAndBytes and LoRA for efficient fine-tuning. The good news? It only takes a few lines of code.
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
)This configuration enables 4-bit quantization using the nf4 format, which is more precise than int4 and ideal for normally distributed weights. Combined with double_quant, it reduces memory usage even further without sacrificing performance.
Then, just pass this config when loading the base model:
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True,
)And just like that, the model is loaded in 4-bit precision and ready to be adapted with LoRA.
👉 For the full code with a practical example, check out the Notebooks section.
QLoRA is about autonomy
Techniques like LoRA and QLoRA represent a major leap in how we approach fine-tuning large-scale language models.
By combining efficient quantization with lightweight adapters, QLoRA makes it possible to train multi-billion parameter models using accessible infrastructure.
This marks an important step toward democratizing access to high-performance, customized LLMs. What once required GPU clusters and million-dollar budgets can now be done in a startup lab, a university research center, or even, in some cases, on our own laptop!
If you work with LLM-based products, academic research, or simply want to experiment with local fine-tuning on limited resources, QLoRA is definitely worth exploring.