
How to run Hugging Face models directly in VS Code with Copilot Chat


If you already use Visual Studio Code, you’re probably familiar with the power of GitHub Copilot Chat to speed up development.
Now, imagine if you could try out cutting-edge large language models (LLMs) available on Hugging Face directly in your IDE.
With the new Hugging Face Provider extension for GitHub Copilot Chat, this becomes a reality!
With this plugin, we can integrate Hugging Face’s Inference Providers directly into Copilot Chat and access state-of-the-art open models like Kimi K2, Qwen 3 Coder, DeepSeek V3.1, and others, without ever leaving your editor. 🚀
How to set it up
The Hugging Face Provider for GitHub Copilot Chat extension adds a new model provider to Copilot Chat, allowing you to use any LLM supported by Hugging Face’s Inference Providers right inside VS Code.
Prerequisites
Before getting started, you’ll need:
Visual Studio Code version 1.104.0 or later
A Hugging Face account and an access token with the
inference.serverlesspermission
Just log in to Hugging Face, go to Settings → Access Tokens, and create a token as shown in the image below:
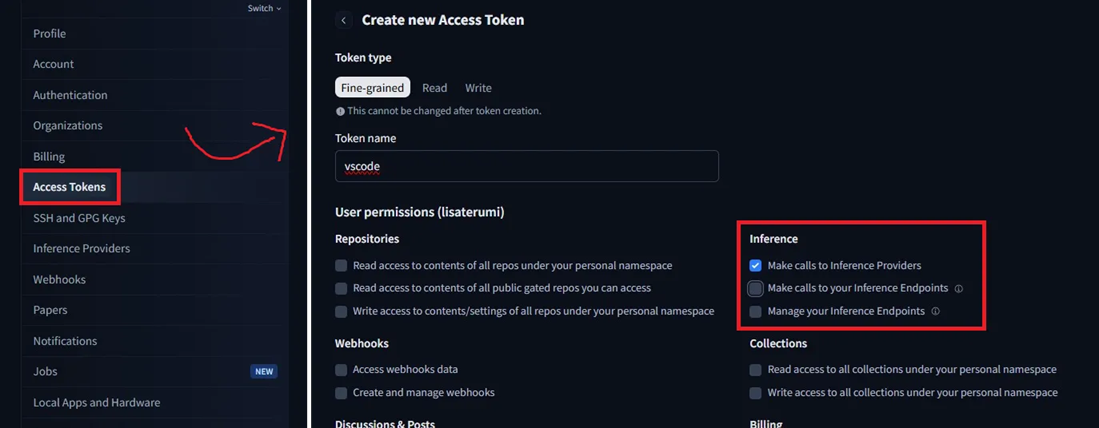
Copy the value of the generated token, as you will need to provide it to the extension inside VS Code.
Follow our page on LinkedIn for more content like this! 😉
Installing the extension
Just follow these steps:
Install the extension: Inside VS Code, go to the Extensions view (Ctrl + Shift + X) and search for “Hugging Face Copilot Chat” in the Marketplace. Once you find the extension, click to install it.
Open Copilot Chat from the “View → Chat” menu or by pressing Ctrl + Alt + I. This will open the chat sidebar.
Click the model selector on “Manage Models” as shown in the image below:
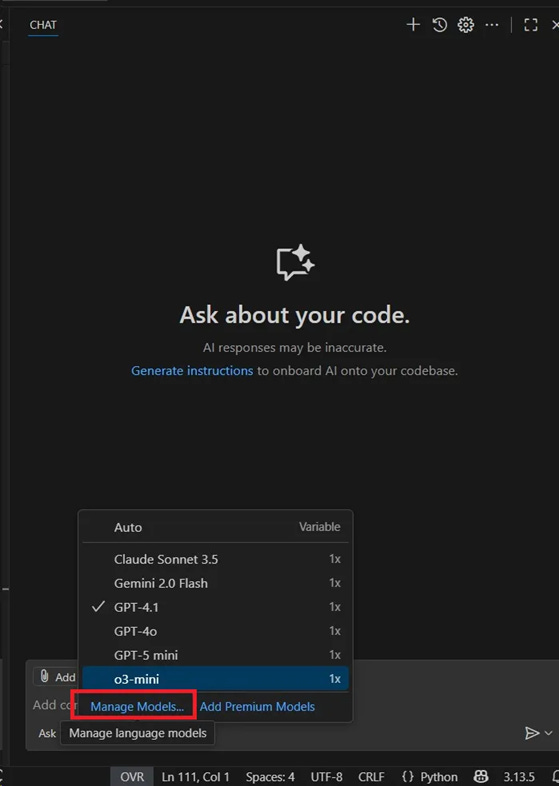
And select the “Hugging Face” provider.

Now, enter the Hugging Face token you generated earlier.

Choose the desired models: After connecting, you’ll see the list of available models. Select the models you want to add to your model selector, such as Qwen3-Coder or Kimi-k2.
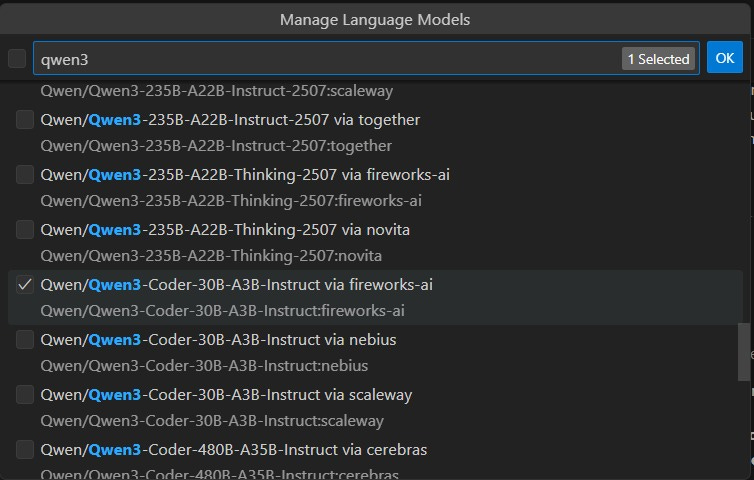
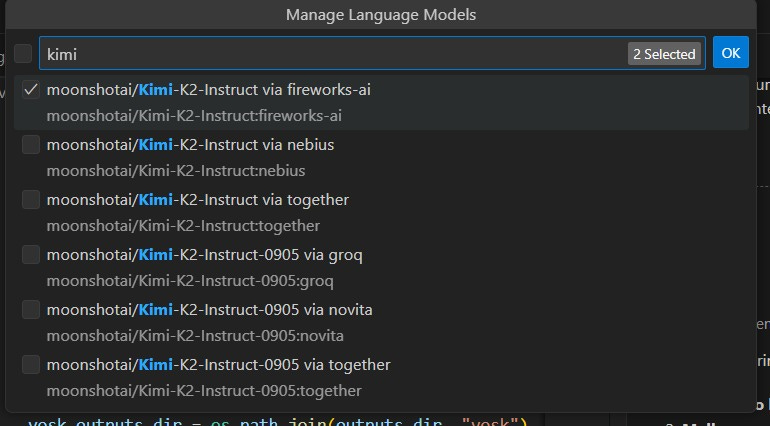
Done! Now you can call these LLMs directly within Copilot Chat, easily switching between providers and models.
Using the models
Now that we have the models selected, to use them, simply go to the chat area in VS Code, select the desired model, and ask your question.
Example:
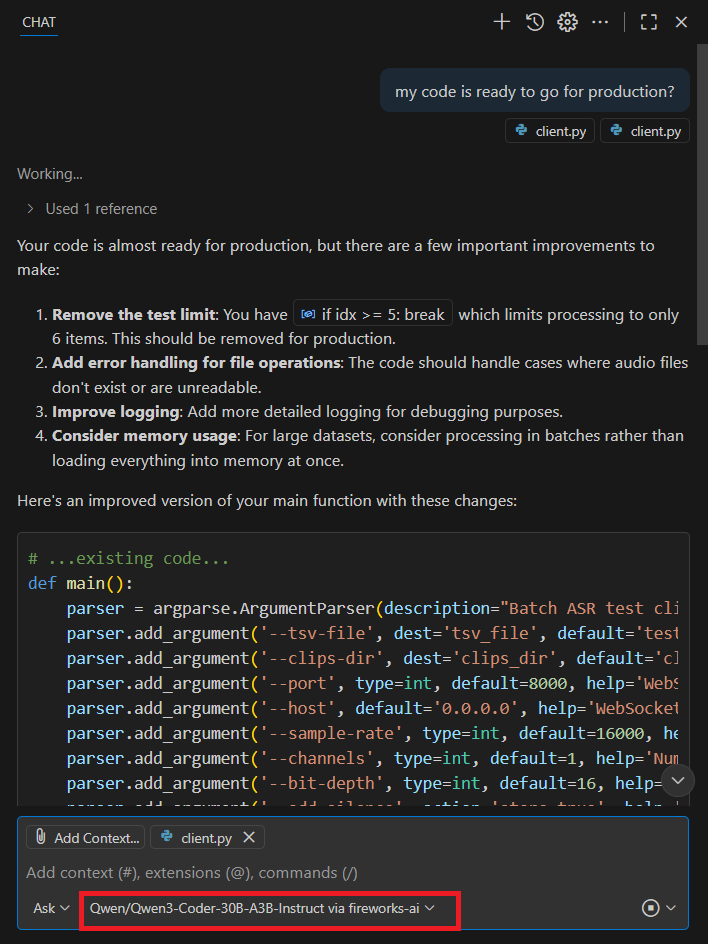
Why use this provider
With this extension, we can:
Access cutting-edge models from the open-source community.
Use a unified API to work with multiple providers (Cerebras, Cohere, Fireworks AI, Groq, HF Inference, Hyperbolic, Nebius, Novita, Nscale, SambaNova, Together AI, and others).
Leverage high-availability, low-latency infrastructure.
Enjoy transparent pricing: you only pay what each provider charges, with no hidden fees.
Benefit from a generous free plan: monthly credits for testing, plus the option to subscribe to PRO/Team/Enterprise plans (initial credit + pay-as-you-go).
Conclusion
This integration is a major step for developers who want to accelerate the experimentation cycle with cutting-edge LLMs directly in their development environment, without having to build an entire inference infrastructure on their own.
If you work with AI and already use GitHub Copilot, it’s definitely worth trying this new Hugging Face provider.
Hugging Face’s free plan already provides enough credits to start experimenting. In just a few clicks, you can switch between multiple open-source models and discover which one best fits your use case.
What do you think of this new extension? Have you tried any of the latest models yet? Share your experience in the comments! 👇