
How to Run LLMs Locally with GPT4All
Run AI models on your own computer or laptop, without needing GPUs or calling APIs.


Large Language Models (LLMs) are revolutionizing how we interact with artificial intelligence.
Running these models locally, without relying on cloud services, has several advantages: greater privacy, lower latency, and cost savings on APIs.
This is the first post in a series presenting six ways to run LLMs locally. Today, we’ll talk about GPT4All, one of the most accessible and practical options.
What is GPT4All?
GPT4All is an open-source application with a user-friendly interface that supports the local execution of various models.
It was developed to democratize access to advanced language models, allowing anyone to efficiently use AI without needing powerful GPUs or cloud infrastructure.
Why use GPT4All?
Running GPT4All locally offers a range of benefits:
Privacy: Since data doesn’t need to be sent to the cloud, you have full control over your information.
Speed: Running directly on your hardware means responses aren’t dependent on network latency.
Cost: By using open-source models, you avoid the cost of API calls.
Prerequisites
Before you begin, ensure your system meets the basic requirements, including:
A computer with at least 8 GB of RAM (preferably 16 GB for optimized performance).
A processor with good multitasking capacity.
A compatible operating system (Linux, Windows, or macOS).
Steps to run GPT4All locally
Here’s a simple step-by-step guide to set up GPT4All in your local environment:
1. Installation
Download the installation file and follow the instructions (Windows, Linux, and Mac).
2. Selecting the Model
Open the application and click "Find Models."
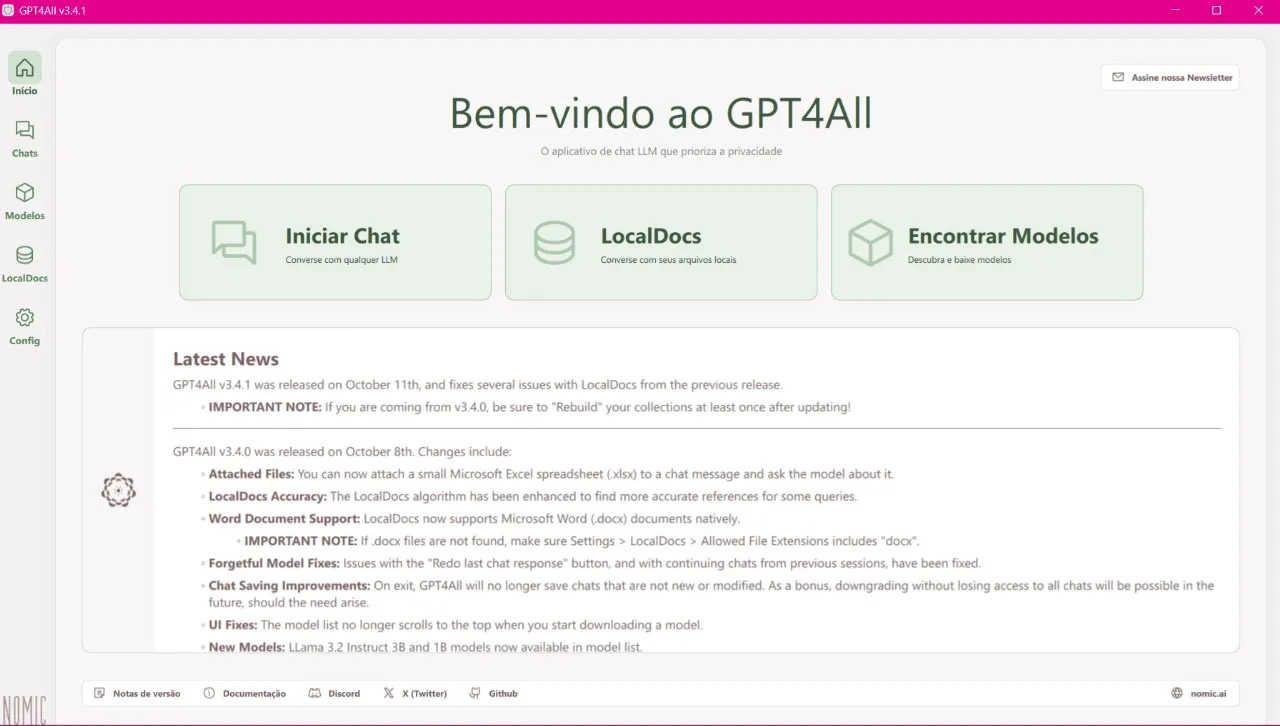
Click "Install a Model."
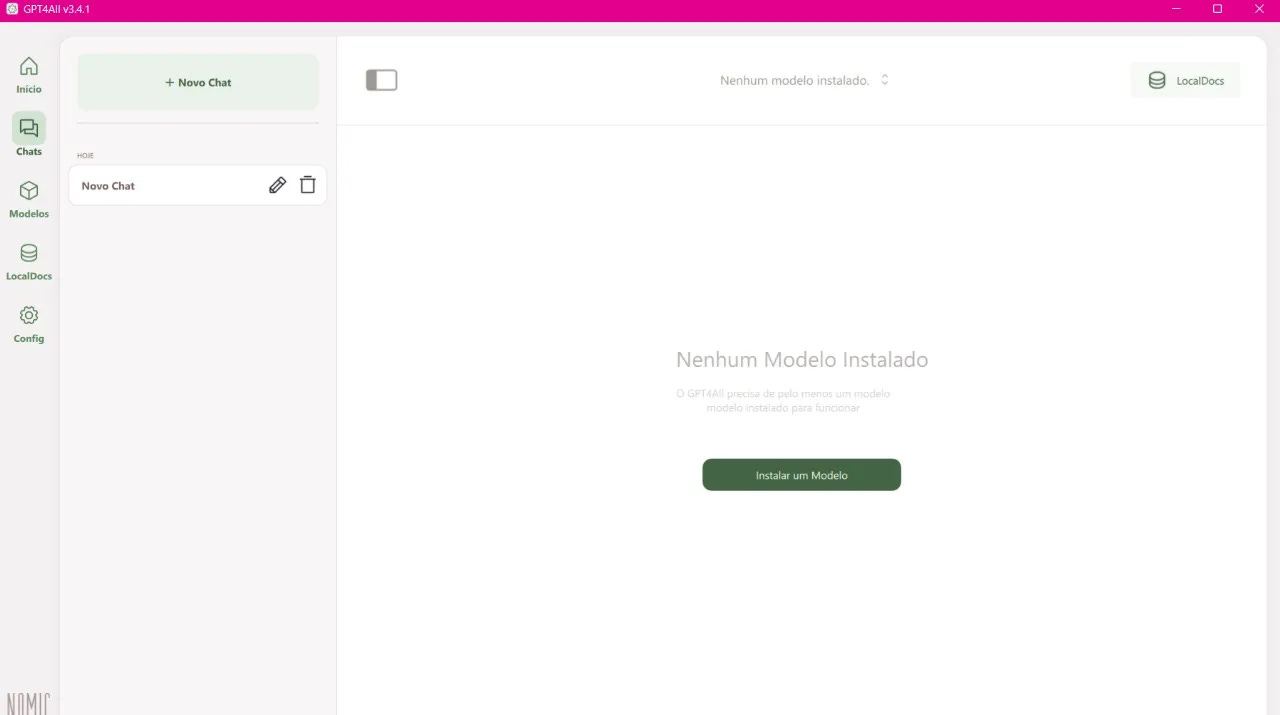
To start, I recommend Llama 3.2 3B Instruct, a multilingual model from Meta that is highly efficient and versatile.
With 3 billion parameters, Llama 3.2 3B Instruct balances performance and accessibility, making it an excellent choice for those seeking a robust solution for natural language processing tasks without requiring significant computational resources. The instruct version is instruction-tuned, meaning it’s optimized for dialogue use cases.
You can try other models, such as Phi-3, Gemma 9B, Mistral -7B, and even larger models, but keep in mind that GPT4All is optimized for running inference on models ranging from 3 to 13 billion parameters on CPUs of laptops, desktops, and servers.
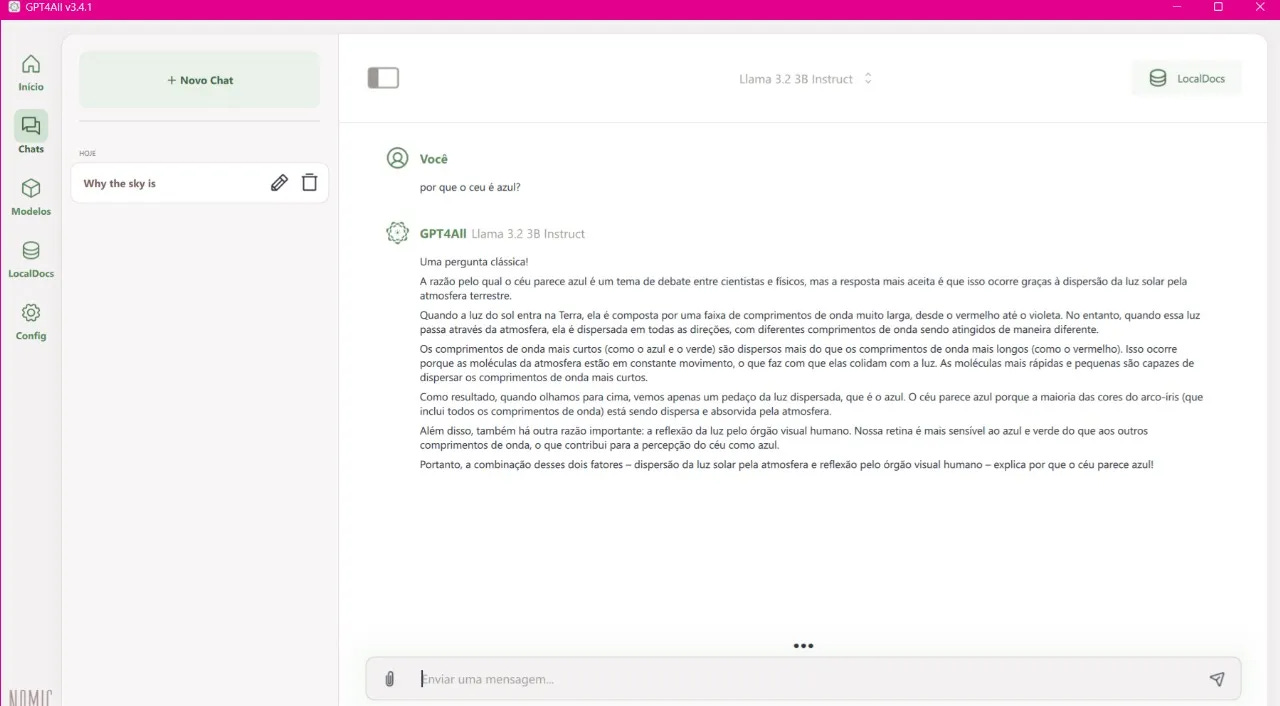
3. Starting a Conversation
Now, simply click to start a new conversation and chat with your model locally!
All dialogue is processed on your local computer, ensuring security and privacy.
4. Chatting with your documents (RAG)
With GPT4All, you can directly interact with your documents, known as RAG, without any coding required.
RAG (Retrieval-Augmented Generation) combines two processes: information retrieval and text generation. First, the model retrieves relevant data from an external knowledge base, such as documents or databases. Then, it uses this data as context to generate more accurate and grounded responses, ensuring that the generated content is based on retrieved facts, not just the model’s internal knowledge.
All your data stays stored locally, with GPT4All handling retrieval privately on-device to fetch relevant data to support your queries to your LLM.
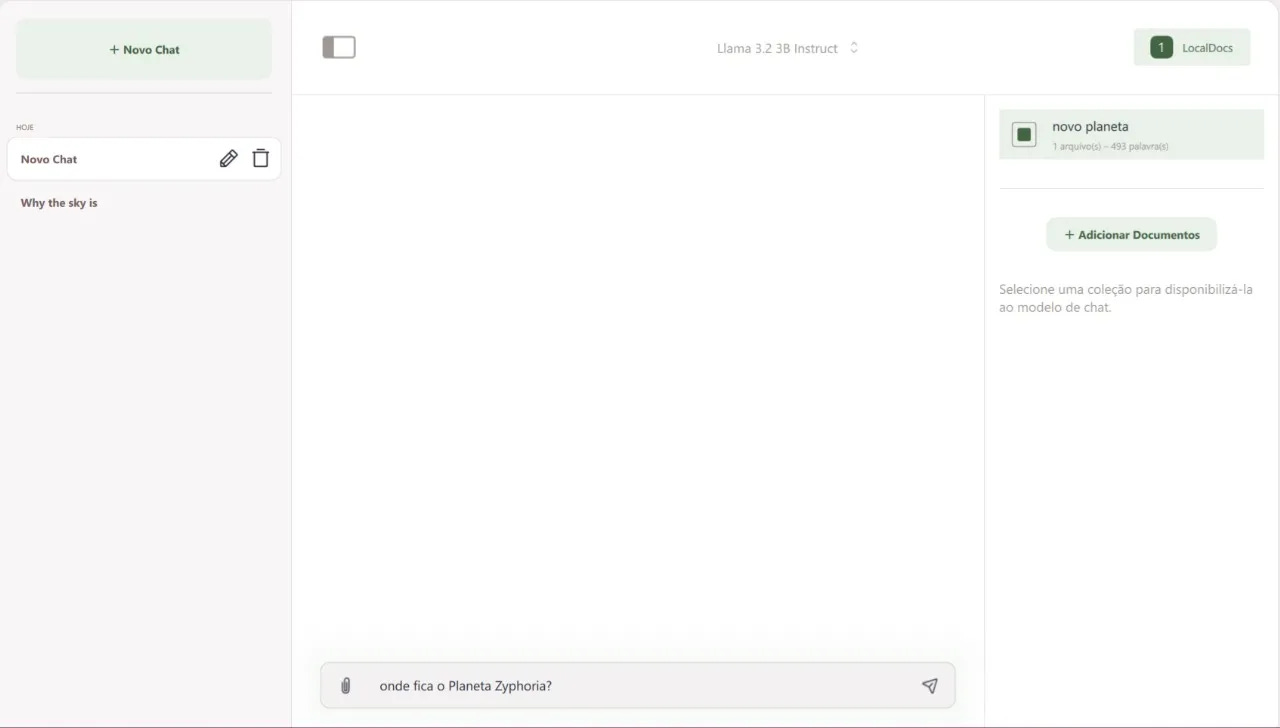
To interact with your documents, you first need to add the document collection as shown in the image below.
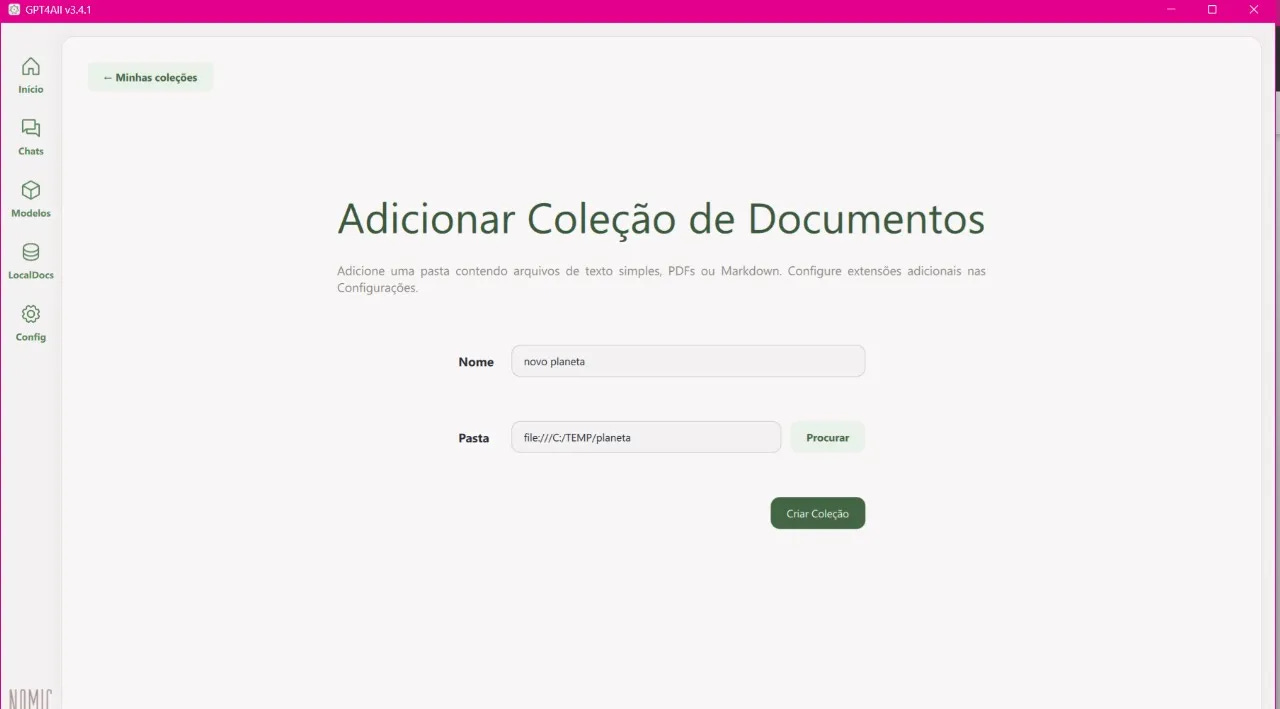
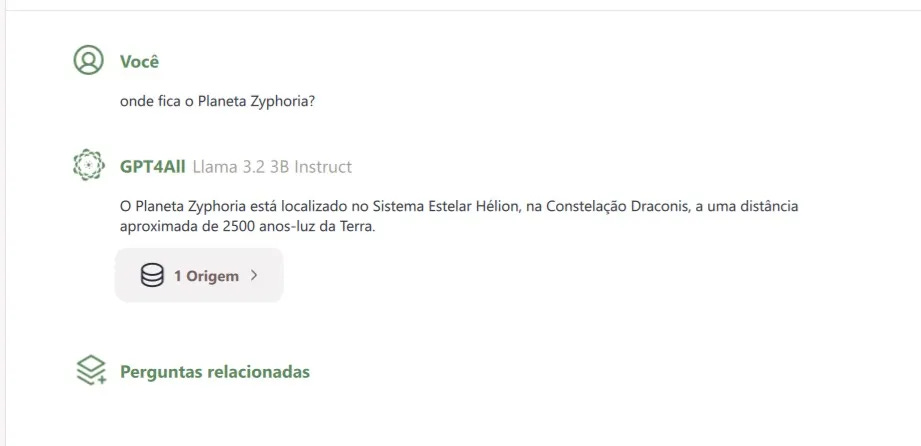
In this example, I added a folder containing a TXT file with information about a new (fictional!) planet called Zyphoria, located in the Helion Star System, Draco Constellation, approximately 2,500 light-years away from Earth.

After inserting the collection, return to the chat and select the collection name containing the file you want to interact with (in my case, "new planet").
From now on, the model will respond based on the information in your collection. Besides giving the answer, it also displays the source, i.e., the data source it used to base the response on.
5. Running via Python
If you prefer, you can also install and run the tool using pip and Python.
pip install gpt4allReference Python code:
from gpt4all import GPT4All
model = GPT4All("Meta-Llama-3-8B-Instruct.Q4_0.gguf") # loads a 4.66GB model
with model.chat_session():
print(model.generate("What is Artificial Intelligence?", max_tokens=1024))
Simply run your Python file to see the response to your question.
Final Considerations
Running LLMs locally with GPT4All is an excellent solution for those seeking privacy, cost-effectiveness, and independence from cloud services, all in a completely free and open-source manner.
GitHub: https://github.com/nomic-ai/gpt4all
This is just the first approach in our series on local LLM execution. In future posts, we’ll explore other equally powerful solutions, each with its own benefits and use cases.
Stay tuned for the next posts! 💗