
Running Models Locally with LM Studio
Unlock the full power of AI on your own computer with LM Studio

In today's Artificial Intelligence landscape, the ability to run models locally provides significant advantages in terms of privacy, data control, and flexibility.
Continuing our series of posts on how to run models locally without relying on external APIs, today we will explore the features of LM Studio.
In this post, we’ll walk through some steps and tips to help you get started using LM Studio to run models locally.
Key Features of LM Studio
LM Studio offers a variety of functionalities and features, such as:
Model parameter customization: This allows you to adjust temperature, maximum tokens, frequency penalty, and other settings.
Chat history: You can save prompts for future use.
UI parameters and tips: Hover over information buttons to look up parameters and model terms.
Cross-platform: LM Studio is available on Linux, Mac, and Windows operating systems.
Machine specifications check: LM Studio checks your computer's specs, such as GPU and memory, and reports which models are compatible. This prevents downloading a model that may not run on a specific machine.
AI Chat and Playground: Chat with a large language model in a chat format and experiment with various LLMs by loading them simultaneously.
Local inference server for developers: Allows developers to set up a local HTTP server similar to OpenAI’s API.
Installing LM Studio
You can download the application according to your operating system by visiting this link:
https://lmstudio.ai
and install it following the instructions.
Loading a Model
The next step is to load the language models you want to run. The homepage shows the main available LLMs and provides a search bar to filter specific models from different AI providers.
In this tutorial, we will use the Phi3-mini-4k-instruct:
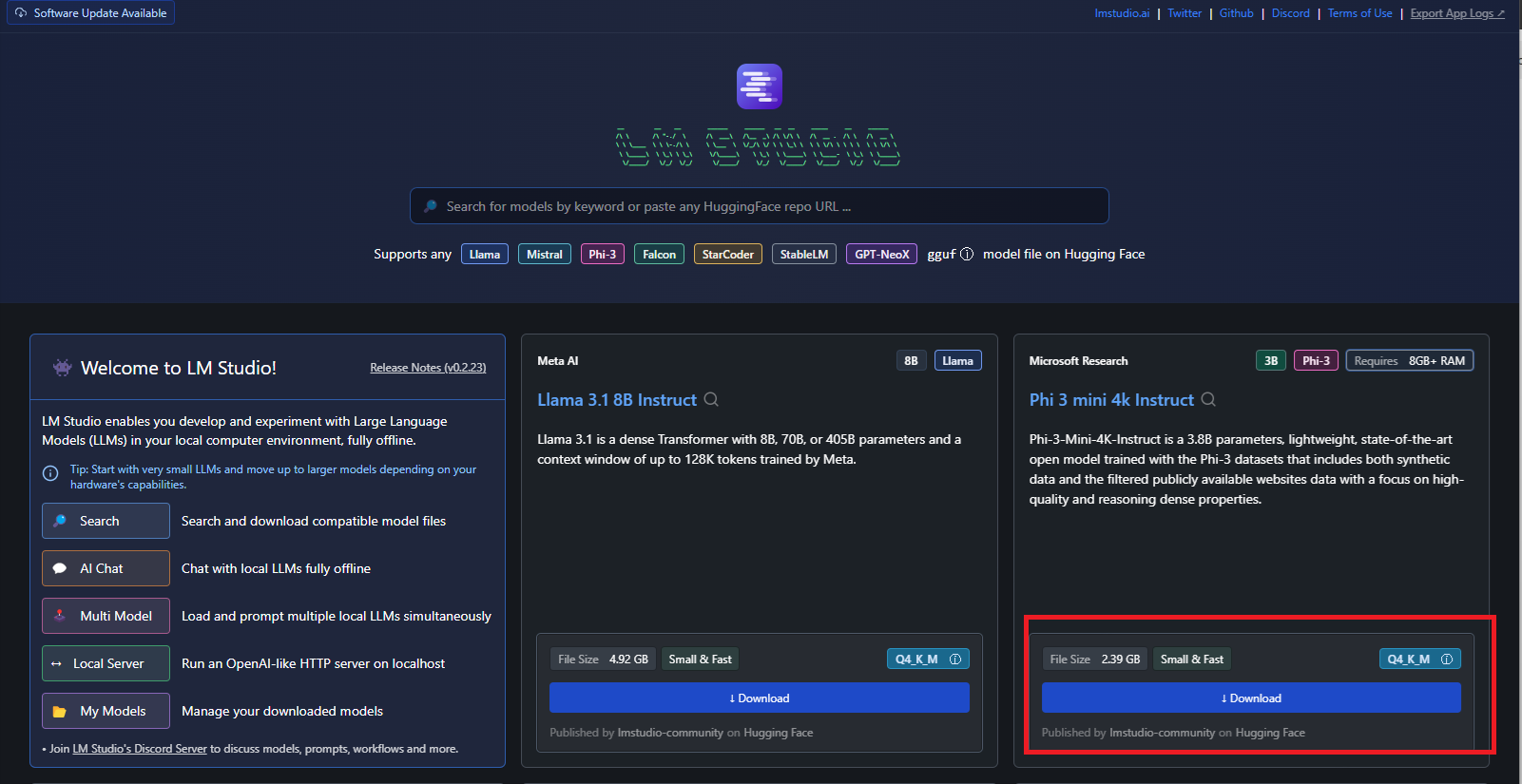
The Phi-3 from Microsoft is a small language model that combines deep learning and artificial intelligence techniques to generate text, understand complex contexts, and provide more accurate responses, fostering more natural interactions between humans and machines.
Start a Conversation
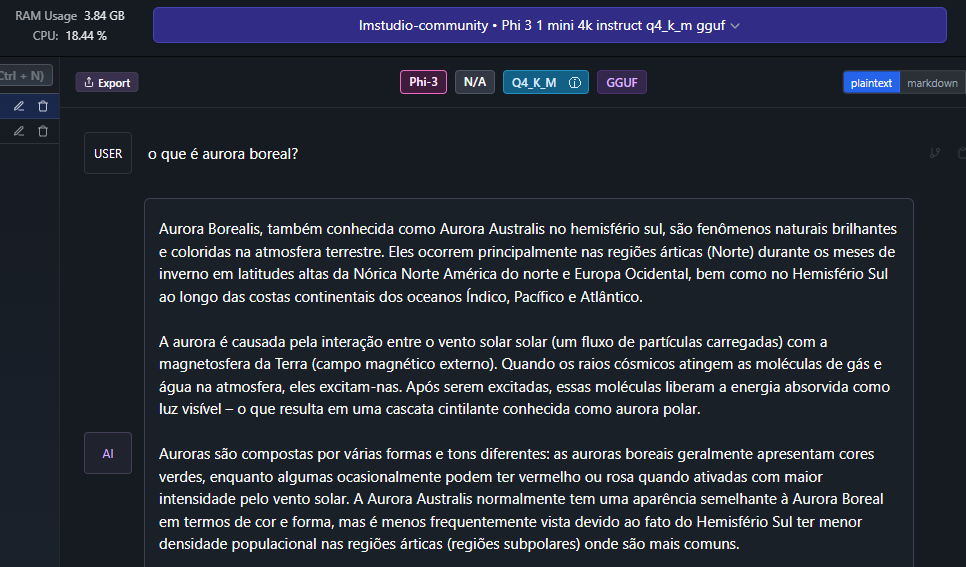
Just click on the speech bubble icon to start a conversation and select the model you want to chat with, in our case, Phi3.
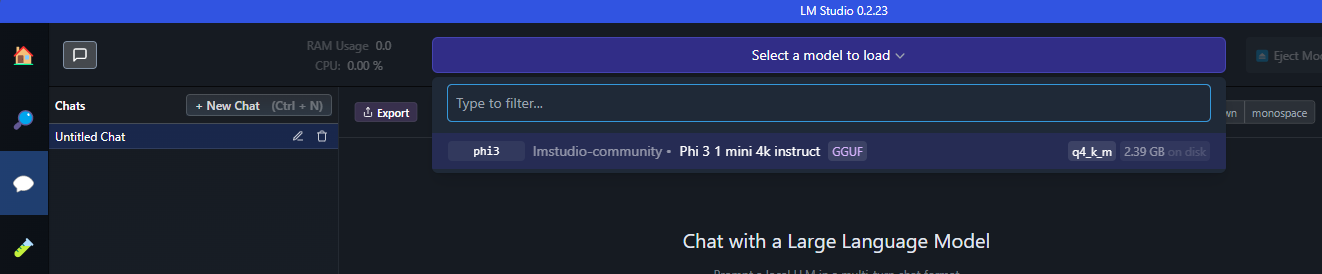
Now you can start chatting with your model!
Setting up a Local Server
With just one click, you can set up a local HTTP server for inference, similar to OpenAI’s API.
Simply go to the arrows menu, as shown in the image below, and click to Start the Server.
It will run on port 1234 by default, but you can change it if needed.
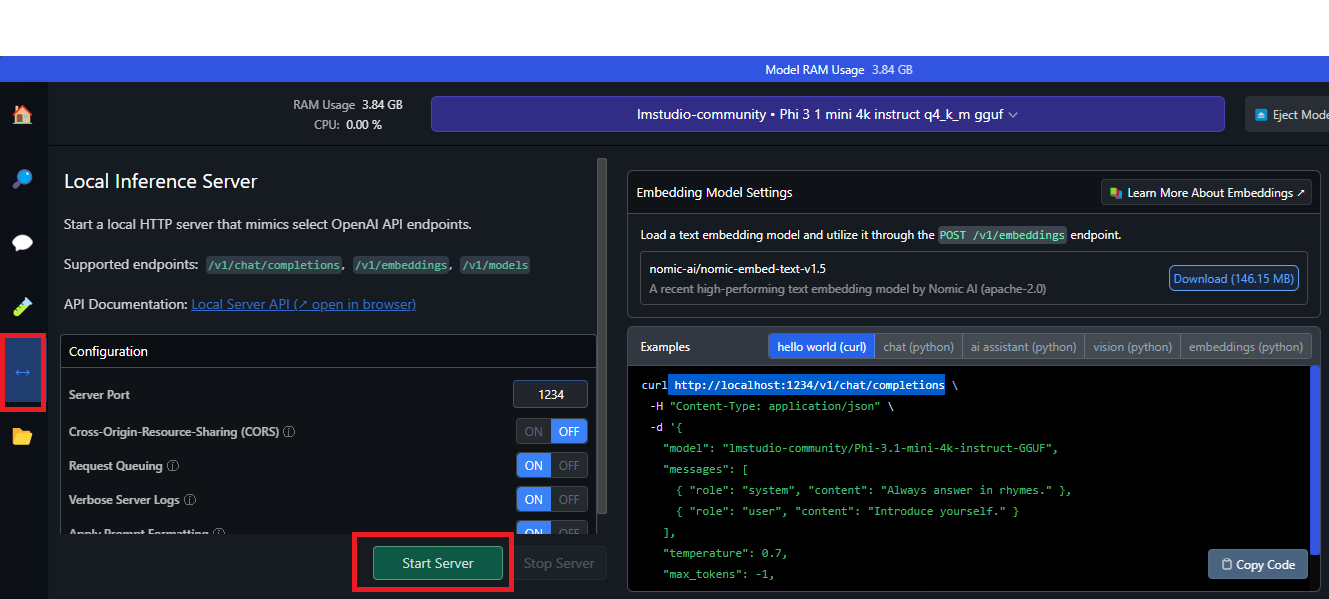
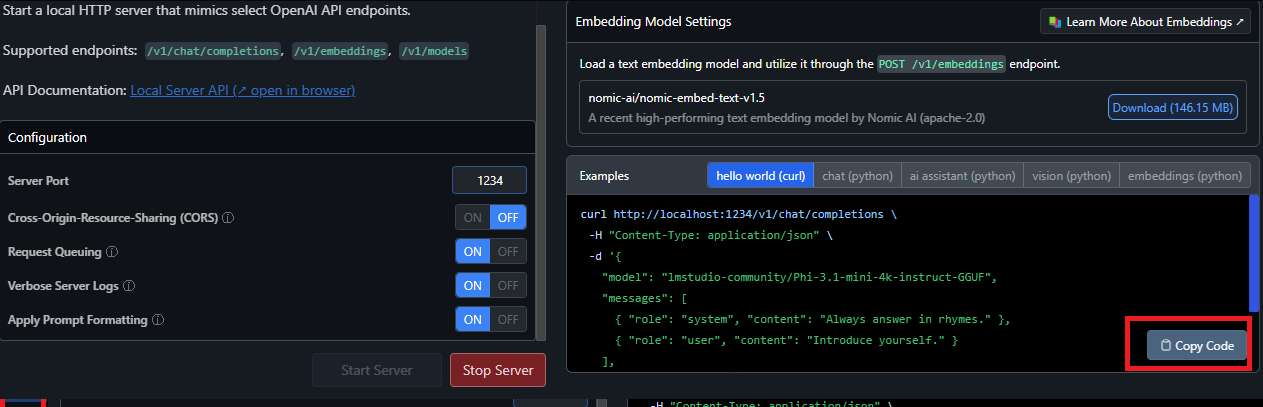
The local server provides sample Curl and Python client requests. With this feature, you can build an AI application that uses LM Studio to access a specific LLM.
If you already have an existing application that accesses an OpenAI API, for example, just modify the base URL to point to your local host (localhost).
You can copy the sample command and test it on your computer!
For more details on the API, refer to the documentation.
Hope you enjoyed this post! See you in the next post! ❤️