
Decision Tree: How to Make Intelligent Decisions with Data
With decision trees, the search for answers becomes a clear, structured, and well-grounded process.

Hello!
Continuing the series “Top 8 Machine Learning Algorithms: Everything You Need to Know”, today we will explore decision trees!
This algorithm has been one of the most popular and widely used techniques in the field of artificial intelligence and machine learning.
Decision trees provide an intuitive and visual way to make data-driven decisions, with various applications such as data analysis, trend forecasting, and automated decision-making.
In this article, we will explore what decision trees are, how they work, their advantages and disadvantages, and some practical examples of their use.
You can find the code on Colab at: https://exploringartificialintelligence.substack.com/p/notebooks
What is a Decision Tree?
A decision tree is a predictive model used to make decisions or classify data based on a series of decision rules.
The model is structured hierarchically, with a root node at the top, representing the main decision to be made. From this node, various branches (or child nodes) emerge, each representing a decision or condition to be applied. The leaves of the tree, in turn, represent the output or class of the model, i.e., the final result of the decision.
In simple terms, we can understand the decision tree as a "decision flowchart." The main advantage of this representation is that it facilitates the interpretation and understanding of the decision processes, in addition to being computationally efficient.
How Does a Decision Tree Work?
The construction of a decision tree involves two main steps: selecting the best splits (or attributes) at the nodes and recursively building the tree until a stopping condition is met (such as maximum depth or node purity).
Attribute Selection (or Features): At each node, the algorithm selects the attribute that best divides the data into groups. This choice is based on "purity" metrics, such as entropy.
Recursive Splitting: After selecting the attribute, the dataset is divided into subsets, and the process is recursively repeated for each subset, creating new nodes and branches until stopping conditions are reached, such as complete homogeneity of data in a leaf.
For example, when classifying a dataset of customers as "buy" or "not buy," the algorithm might start with the attribute "age," followed by "income," and so on, until the tree has made all the necessary decisions to classify the data correctly.
Advantages of Decision Trees
Decision trees offer several advantages that make them attractive for various applications:
Ease of Interpretation: One of the biggest advantages of decision trees is that they are highly interpretable and visual. Even someone with no deep technical knowledge can understand how the model reaches a decision.
Minimal Data Preprocessing: Decision trees do not require data to be normalized or transformed, which makes them easy to use with different types of data.
Ability to Handle Missing Data: Decision trees can handle missing data well, as they can be adjusted to ignore missing values during the splitting process.
Flexibility: New options can be added to existing trees.
Disadvantages of Decision Trees
Despite their advantages, decision trees also have some limitations:
Prone to Overfitting: If not well-tuned, decision trees can become very complex and overfit to the training data, leading to poor generalization to new data.
Instability: Small changes in the data can result in a completely different tree structure, making them sensitive to variations in input data.
Low Accuracy in Complex Problems: Simple decision trees may not capture complex relationships between the data and may be less accurate than more sophisticated models, such as neural networks or ensemble methods.
Applications
Decision trees are widely used in various fields, such as:
Medical Diagnosis: Used to diagnose diseases based on symptoms and test results.
Credit and Finance: In the financial sector, decision trees help determine whether an individual is eligible for a loan based on variables such as credit history, income, and age.
Marketing: Can be used to segment customers and make decisions on marketing campaigns by analyzing demographic, behavioral, and purchase history data.
Fraud Detection: Decision trees can help identify suspicious behavior patterns, such as fraudulent financial transactions.
Let's Code!
Imagine we have a dataset of fruits and want to classify them automatically based on three characteristics:
Weight (in grams)
Color (yellow, red, or green)
Shape (round or elongated)
Our goal will be to train a supervised learning model that can correctly identify the type of fruit based on these data using decision trees.
Project Steps:
Data: We create a small dataset with fictional fruit characteristics and their corresponding labels (Banana, Apple, Melon, or Strawberry).
Preprocessing: We convert categorical information, such as color and shape, into numerical values using techniques like Label Encoding. This is necessary because machine learning algorithms work better with numerical data.
Model Training: We use the
DecisionTreeClassifierclass from the Sklearn library to build the model. It learns the rules that associate the data with the fruit classes.Tree Visualization: We generate a graph of the decision tree to understand the decisions made by the model at each step.
Create a file with Jupyter Notebook and paste the code:
# Importing necessary libraries
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
import numpy as np
from sklearn.preprocessing import LabelEncoder
# Generating fictional fruit data
# [Weight (in grams), Color (String), Shape (0=Round, 1=Elongated)]
X = np.array([[190, 'Yellow', 'Round'], # Banana, Yellow, Round
[200, 'Red', 'Round'], # Apple, Red, Round
[220, 'Green', 'Elongated'], # Melon, Green, Elongated
[180, 'Yellow', 'Round'], # Banana, Yellow, Round
[30, 'Red', 'Round'], # Strawberry, Red, Round
[210, 'Red', 'Round'], # Apple, Red, Round
[200, 'Green', 'Elongated'], # Melon, Green, Elongated
[170, 'Yellow', 'Round'], # Banana, Yellow, Round
[210, 'Red', 'Round'], # Apple, Red, Round
[290, 'Green', 'Elongated'], # Melon, Green, Elongated
[50, 'Red', 'Round']]) # Strawberry, Red, Round
# Labels (0=Banana, 1=Apple, 2=Melon, 3=Strawberry)
y = np.array([0, 1, 2, 0, 3, 1, 2, 0, 1, 2, 3])
# Encoding colors (Label Encoding)
label_encoder = LabelEncoder()
X[:, 1] = label_encoder.fit_transform(X[:, 1]) # Encoding the color column
# Encoding shape as numeric values
X[:, 2] = np.where(X[:, 2] == 'Round', 0, 1)
# Converting the X data to numeric type
X = X.astype(float)
# Creating the decision tree classifier
clf = DecisionTreeClassifier()
# Training the model
clf.fit(X, y)
# Visualizing the decision tree
plt.figure(figsize=(12, 4))
plot_tree(clf, filled=True, feature_names=["Weight", "Color", "Shape"], class_names=["Banana", "Apple", "Melon", "Strawberry"], rounded=True, impurity=False)
plt.show()
Result:
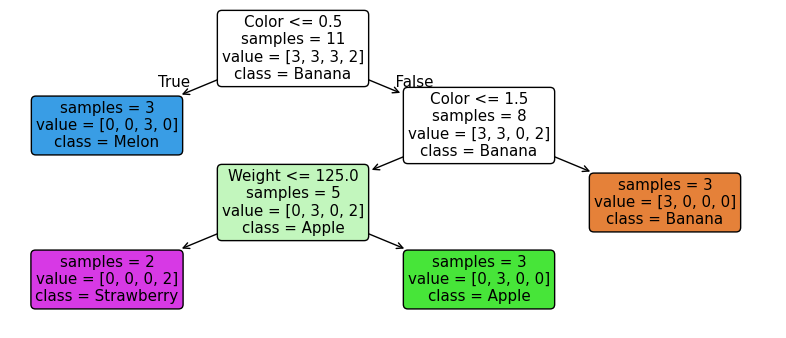
If we traverse the tree, we can understand how the model makes its decisions when classifying each fruit. Each node in the tree represents a question based on the features (such as "Is the weight greater than 200 grams?" or "Is the color red?"), and each branch leads us to a more specific data subgroup.
As we follow the branches, we reach the leaves, which represent the final classes, such as Banana, Apple, Melon, or Strawberry. This hierarchical structure makes it easier to interpret the model and helps us identify the most relevant features for classification.
For example, if a fruit weighs 190 grams, is yellow, and has a round shape, the tree may decide it is a Banana by following the corresponding path. This process is known as "inference," and the clarity with which decision trees represent these rules is one of the reasons why they are widely used in classification and regression problems.
You can find the code on Colab at: https://exploringartificialintelligence.substack.com/p/notebooks
Conclusion
Decision trees are powerful and intuitive tools in the field of Artificial Intelligence and Machine Learning.
They provide a clear way to make data-based predictions, being particularly effective in classification and regression tasks. Decision trees are ideal for implementing responsible AI systems due to their transparency and interpretability, allowing decisions to be easily explained and audited.
Although they have some limitations, such as the tendency to overfit and instability regarding variations in the data, these disadvantages can be mitigated through techniques like pruning and using ensemble methods like Random Forests.
If you are starting to explore the world of machine learning, decision trees are an excellent entry point, offering both simplicity and effectiveness.
If you wanted to delve deeper into the subject: Decision Trees and Random Forests: A Visual Introduction For Beginners: A Simple Guide to Machine Learning with Decision Trees (English Edition)
In the next article, we will explore Random Forest, so don’t miss it!! 🔥