
Top 8 Machine Learning Algorithms: Everything You Need to Know
How to Choose the Right Machine Learning Algorithm for Your Project


The world of Machine Learning is constantly evolving and has transformed the way we interact with technology.
From movie recommendations to medical diagnoses, machine learning algorithms are responsible for learning from data and generating intelligent, automated solutions.
But with so many techniques available, how do you know which one to choose?
This is the first post in a series that will explore the key machine learning algorithms. In each new article, we will detail a specific algorithm, explaining how it works, its best applications, and how you can use it in your own projects.
Let’s start by understanding the basic concepts that underpin this technology.
What is Machine Learning?
Machine learning is an area of artificial intelligence (AI) that enables computers to learn from data without the need for explicit programming.
Instead of following fixed rules, machine learning systems identify patterns in data and use these patterns to make predictions or decisions.
Types of Machine Learning
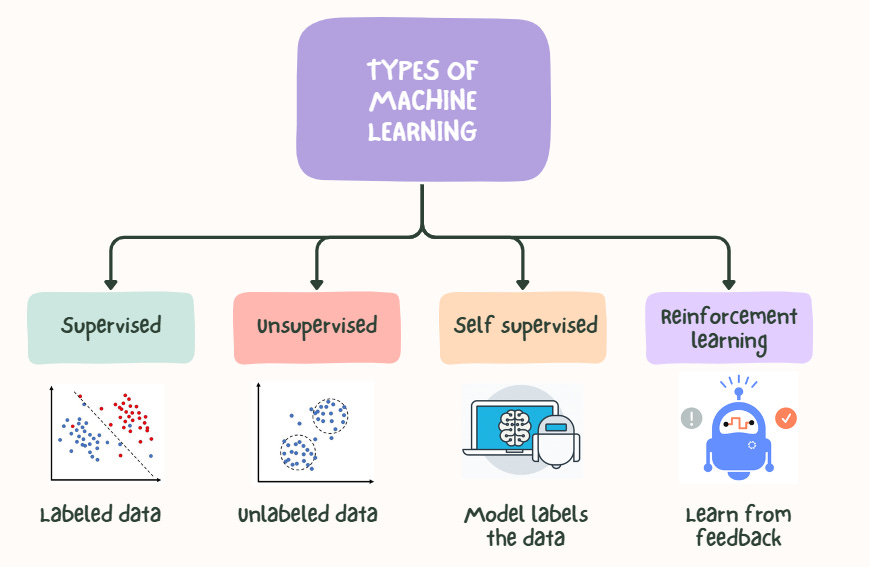
Machine learning can be divided into three main categories, each with distinct characteristics and specific applications.
I won't cover self-supervised learning here, but we’ll talk about it in another post :)
The choice of which type of learning to use depends on the problem you're trying to solve and the data you have available.
The three main approaches are:
1. Supervised Learning
In supervised learning, the algorithm learns from labeled (or annotated) data. In other words, the model is trained with examples where both the input and the desired output are already known.
The goal is for the model to learn to predict the correct output for new inputs, based on the patterns identified in the training data.
Examples of Applications:
Classification: Identifying whether an email is spam or not, based on a set of labeled email examples.
Regression: Predicting the value of a continuous variable, such as the price of a house based on features like size and location.
Advantages:
The model has a "clear direction" on what to learn since it has examples with defined answers.
High accuracy, especially when many labeled data are available.
Disadvantages:
Requires a large number of labeled data, which can be challenging in some cases.
The model may struggle to generalize to new data that doesn’t fit well into the patterns identified in the training data.
2. Unsupervised Learning
Unlike supervised learning, in unsupervised learning, the algorithm works with unlabeled data, meaning no annotations are provided.
The model tries to identify hidden patterns or structures in the data, such as clusters or associations, without having a specific answer to predict.
Examples of Applications:
Clustering: Grouping customers based on their common purchases, without knowing in advance which groups exist.
Dimensionality Reduction: Reducing the number of variables in a dataset while preserving the most relevant information.
Advantages:
Doesn’t require labeled data, making the process more flexible and suitable when there are no known answers.
Can reveal hidden patterns in the data that might not be easily perceived.
Disadvantages:
Interpreting the results can be more challenging, as there is no clear "label" for the data.
It can be harder to validate the accuracy or effectiveness of the model, as there’s no predefined answer to verify.
3. Reinforcement Learning
Reinforcement learning is a more dynamic approach, where an agent learns to make decisions through interactions with the environment.
Instead of being trained with predefined data or answers, the agent receives feedback based on rewards or penalties, depending on the actions it takes.
Examples of Applications:
Games: Training agents to play video games or board games, such as chess or Go.
Robotics: Teaching robots to perform complex tasks, like walking or picking up objects.
Advantages:
Can be used in environments where the answers are not predefined and are learned through trial and error.
Ideal for problems where the sequence of decisions is important (like in games and robotics).
Disadvantages:
Requires an interactive training environment and is often more complex to implement.
It may take longer to achieve significant results, as it relies on continuous feedback.
Each type of algorithm has its own advantages and is applicable to different scenarios. Understanding which approach to use in your project is crucial for the success of implementing an effective model.
What’s Coming Next: Algorithms We’ll Explore
Now that you know the different types of machine learning, let’s take a look at the 8 algorithms we’ll be exploring throughout the series.
Each of these algorithms has its own characteristics and is applicable to a variety of problems. In the upcoming posts, we’ll dive into how each one works and understand when and how to use them to get the best results, starting with supervised learning.
1. Linear Regression
Let’s start with one of the simplest and most powerful algorithms: linear regression. It is used to predict continuous values and is ideal for situations where there is a direct relationship between the variables. Imagine predicting the price of a house based on its square footage and location.
2. Logistic Regression
Logistic regression is an extension of linear regression, but focused on binary classification problems. It is widely used to predict the probability of an event occurring, such as in fraud detection, medical diagnosis, or classifying emails as spam. We’ll explore how it can be effectively applied in binary prediction scenarios.
3. Decision Tree
Decision trees are versatile and intuitive tools. They help make decisions by splitting the data into various paths, like a flowchart. It is one of the easiest algorithms to interpret, making it very popular in classification and prediction problems.
4. Random Forest
Random Forest is an ensemble algorithm that combines multiple decision trees to improve accuracy and reduce the risk of overfitting. It is ideal for more complex problems where you need higher accuracy and robustness.
5. Support Vector Machines (SVM)
SVM is a powerful algorithm for classification and regression, and is particularly useful when classes are well-separated. It finds the line or hyperplane that divides the data most efficiently, maximizing the margin between the classes. Ideal for situations where precision is crucial.
6. K-Nearest Neighbors (KNN)
KNN is one of the simplest and most effective classification algorithms. It classifies data based on the proximity of points to their nearest neighbors. We’ll explore how it can be applied to classification problems, such as pattern recognition or medical diagnosis.
7. Neural Networks
Neural networks are the core of many modern AI innovations, such as speech and image recognition. They are inspired by the workings of the human brain and are extremely powerful for solving complex problems like image classification and natural language processing.
8. K-Means (Unsupervised Learning)
In unsupervised learning, K-Means is one of the most popular algorithms for data clustering. It divides the data into clusters (groups) based on their similarities. If you need to segment customers into different groups, K-Means might be the perfect solution.
Each of these algorithms will be detailed in the upcoming posts of the series, with examples and tips for implementing each technique effectively.
If you want access to the Colab (Notebook) with the practical code of these algorithms in action, visit: https://exploringartificialintelligence.substack.com/p/notebooks
Stay tuned!! 🩷