
Gemma 3: What’s New in Google’s Multimodal Model

The third generation of the Gemma model family, developed by Google DeepMind, represents a significant technical advancement toward multimodal, efficient, and accessible models.
Today, we’ll dive into the architectural changes, expanded capabilities, and practical impact of Gemma 3, including its quantized version, QAT (Quantization-Aware Training).
With a focus on on-device use, intelligent compression, and understanding of images and multiple languages, this new family marks an important evolution in Google’s line of open models.
To view the Colab notebook with an example of inference using Gemma 3, visit: https://exploringartificialintelligence.substack.com/p/notebooks
What is Gemma 3?
Gemma 3 is a new-generation model in the Gemma family, ranging from 1B to 27B parameters, and now with multimodal support (text + image). This version inherits the efficient architecture of previous models but includes specific optimizations to support:
128K context tokens (in larger models)
Image understanding via an adapted SigLIP encoder
Interleaved local-global attention to reduce memory usage (KV-cache)
A new balanced multilingual tokenizer
Key Innovations in Gemma 3
Below are the highlights that make Gemma 3 particularly appealing for AI practitioners:
Multimodal Support (Text + Image)
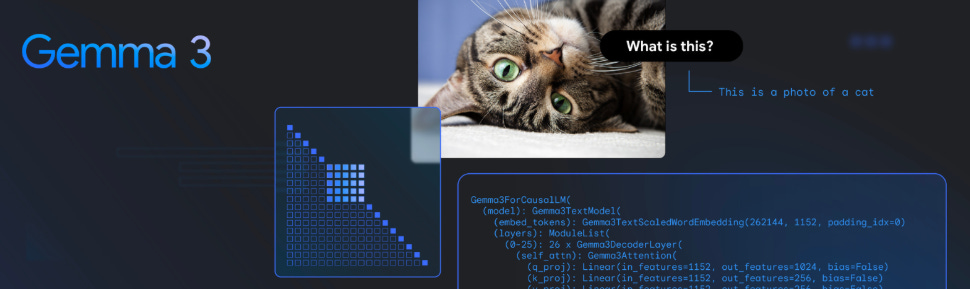
Gemma 3 can now understand images! It includes a visual encoder based on SigLIP, specially fine-tuned for this version.
Images are processed using a technique called Pan&Scan, which adapts various aspect ratios and resolutions to work with square images of 896x896 pixels.
These images are converted into 256 vectors ("soft tokens") by a MultiModalProjector, which significantly reduces inference computational cost.
Comparison with PaliGemma 2:
PaliGemma is better suited for tasks like image segmentation and object detection. However, Gemma 3 has advantages in general multimodal tasks, multi-turn conversations, and zero-shot generalization.
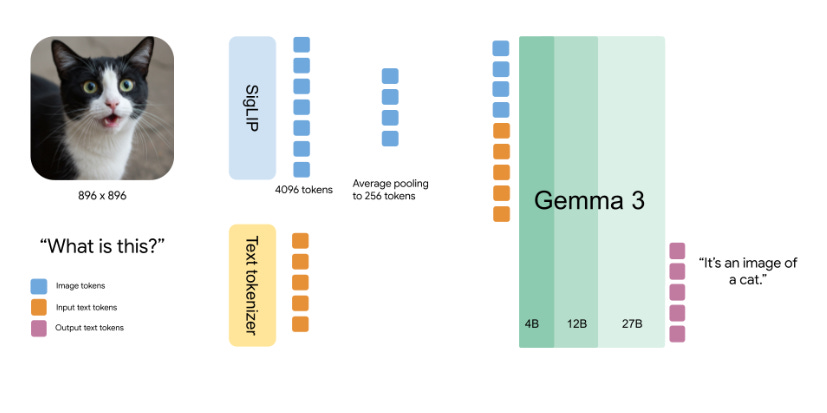
The model uses bidirectional attention on images, unlike the traditional unidirectional attention in text.
This means that each “piece” of the image connects with all the others simultaneously, like assembling a puzzle. In contrast, with text, since the task is to generate the next word, the attention needs to be sequential.
Efficiency and Extended Context
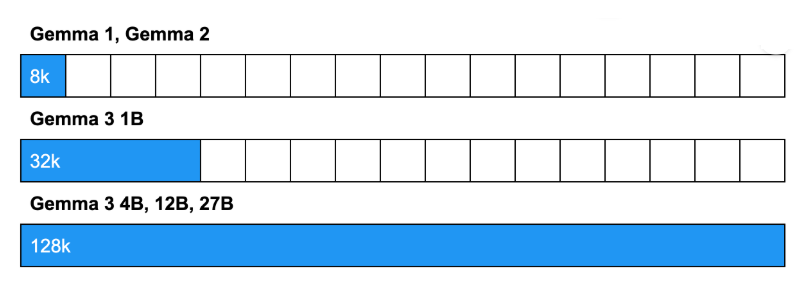
Gemma 3 was designed to handle long contexts of up to 128,000 tokens in the larger models (12B and 27B), enough to analyze an entire novel, 500 images, or perform analysis on extensive documents.
How does it achieve this?
New interleaved attention pattern (5:1): 5 layers with local attention + 1 layer with global attention, instead of the 1:1 alternation used in Gemma 2.
Lower memory usage in the KV-cache: This is crucial for long-context applications.
Improved “Multilingualism”
Gemma 3 adopts the same tokenizer used in Gemini, with a vocabulary of 262K tokens and based on SentencePiece.
The pretraining data mix was expanded with a greater variety of languages (both monolingual and parallel), resulting in:
better performance in low-resource languages
more balanced output across languages
reduced Anglocentric bias.
Important: Previous versions of the tokenizer are not compatible with Gemma 3.
Performance and Impact
The Gemma 3-27B ranked among the top 10 models on LM Arena (April 2025)
It outperforms larger models on several benchmarks while maintaining efficiency to run on consumer GPUs.
The 1B-IT version, text-only, is optimized for mobile and embedded devices, making AI applications more accessible and private.
New Quantized Version (QAT)
Google also released quantized models with QAT (Quantization-Aware Training), optimized to run on consumer GPUs, local TPUs, and mobile devices.
These models, with 4-bit weights, maintain high performance while drastically reducing:
memory consumption (VRAM)
inference time
energy requirements.
Example: the Gemma 3 1B QAT model can run on smartphones with NPU, edge devices, or laptops without a dedicated GPU.
QAT was implemented in an integrated way during training, avoiding the common performance losses of post-training quantization.
The quantized models are available on HuggingFace and Gemmaverse.
The quantized version can be run on Google Colab, even using only the CPU.
Output:
I'm Gemma, a large language model created by the Gemma team at Google DeepMind. I’m an open-weights model, which means I’m widely available for public use!
I can take text and images as inputs and generate text as output.
It’s nice to meet you! To see the complete Colab notebook with the inference example using Gemma3, visit: https://exploringartificialintelligence.substack.com/p/notebooks.
Conclusion
Gemma 3 represents an important advancement in building lighter, more efficient, and more accessible multimodal models.
With integrated computer vision, a larger context window, and multilingual improvements, it offers cutting-edge features without requiring expensive infrastructure.
The quantized QAT versions complete the ecosystem, enabling this state-of-the-art technology to run on smartphones, edge devices, and resource-constrained environments without losing performance.
This evolution opens doors for developers and researchers to create richer, more responsive, and inclusive AI experiences—even on devices with limited resources.
The new models are available on Ollama (see how to use Ollama here), on HuggingFace, and Kaggle.
I hope this article was helpful - see you next time! 💜