
Multimodal Models: The New Frontier of Artificial Intelligence


Artificial intelligence is undergoing a silent but profound transformation.
Where previously models (LLMs) could only process text, they can now understand and generate information in multiple formats, such as text, image, audio, and video.
These are multimodal models (MLLMs), which integrate various modalities into a single representation to perform complex tasks.
Follow our page on LinkedIn for more content like this! 😉
What are multimodal models
A multimodal model is capable of integrating different types of data. For example, it can analyze an image, read a caption, and answer a question about the visual content.
Instead of treating text and image separately, the model creates a shared representation, learning how different modalities relate to each other.
When we show a photo of a cat to one of these models, it not only identifies pixels and shapes, but connects that visual information with all the textual knowledge it has about cats, creating an integrated understanding.
In practice, this means the model understands context in a way much closer to humans, since we also combine senses (vision, hearing, language) to interpret the world.
Practical applications
Multimodal models are transforming various sectors:
Healthcare: interpretation of exams combined with clinical reports
Education: intelligent tutors that analyze videos and explain content
Creative industry: generation of images and videos from textual commands
Security and mobility: analysis of videos and sounds in real time for decision making
Hands-on!
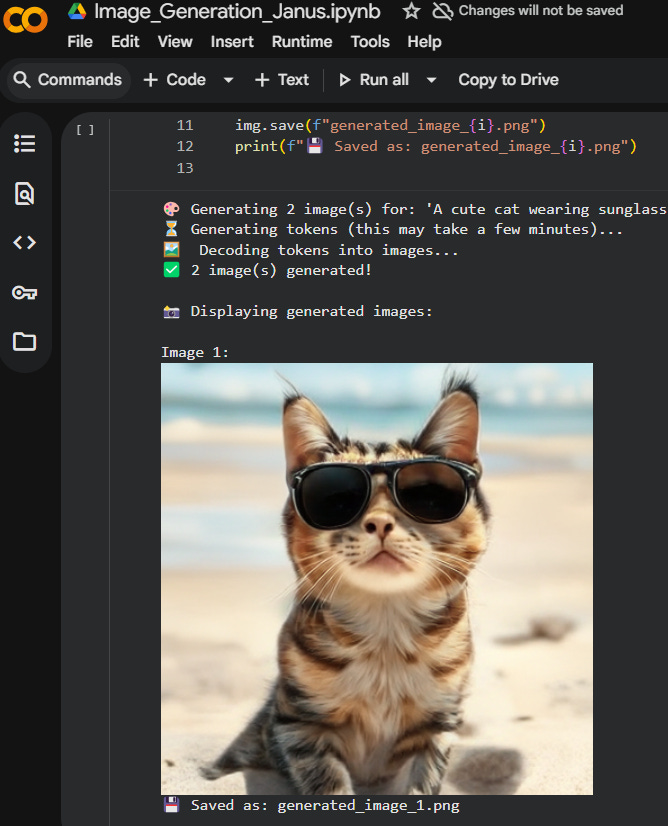
It’s time to see all of this in action.
Let’s explore a practical example of how to generate and interpret images from a prompt, using an open-source model.
The good news is that you can run the example even without GPUs or cloud access, directly in Google Colab.
We will use Janus AI, from DeepSeek, a model that perfectly represents this new multimodal era, capable of both understanding existing images and creating new ones from scratch.
Janus’ differentiator lies in its unified architecture, designed from the ground up to handle both tasks in an integrated way.
In practice, this means we can show Janus a photo and ask it to describe what it sees, identify objects, or generate creative variations of that same image.
And the best part: all of this running on compact models, like Janus-Pro-1B.
👉 Click here to access the Colab.
The Future is Multimodal
We are only at the beginning of the multimodal era.
The ability to process, understand, and generate information across multiple modalities is not just a technical evolution; it’s a fundamental shift in how we interact with machines.
The question is no longer “what can AI do?”, but rather “what will we create with these new capabilities?”
And the answer lies in the hands of developers, creators, and innovators willing to experiment and explore this new territory. 🚀
Read also:
How to run Hugging Face models directly in VS Code with Copilot Chat
Everything You Need to Know About LangChain (Before Starting an AI Project) – Part 1
The future of AI is multimodal. And it has already begun. How about being part of this revolution?
Do you recommend any good books or courses on multimodal machine learning, Elisa? Something that teaches from the ground up (theory) and has hands-on practical experience.